What Are Agent Evals? Why Testing AI Agents Is Harder Than Models
A deep dive into Agent Evaluations (Agent Evals)—why evaluating AI agents is fundamentally different from traditional models, what metrics matter, and how Product Managers can design for reliability and trust.
5/11/20264 min read
AI is undergoing a fundamental shift.
We are moving from systems that generate outputs to systems that take actions. From chatbots that respond, to agents that reason, decide, and execute workflows across tools, data, and environments.
This evolution unlocks massive potential—but it also introduces a new challenge:
How do you know if an AI agent is actually doing the right thing?
In traditional software, testing is deterministic.
In traditional AI, evaluation is output-based.
But with AI agents, neither approach is enough.
This is where Agent Evaluations (Agent Evals) come in—a critical, yet still emerging discipline that sits at the heart of building reliable, trustworthy AI products.
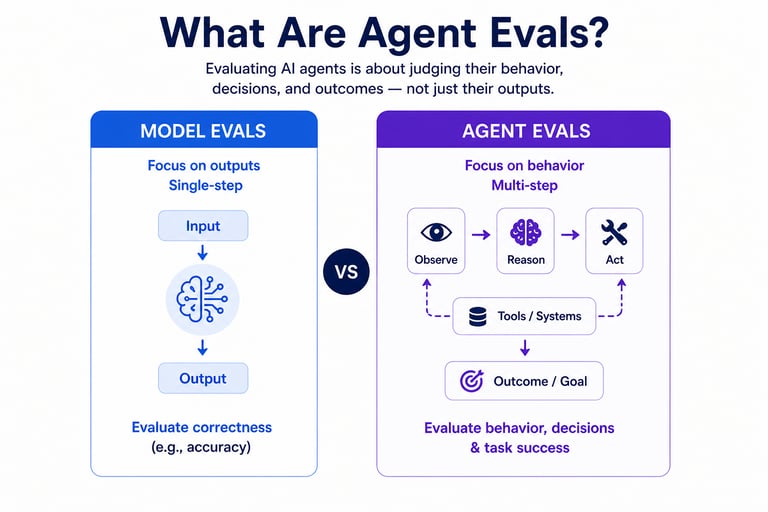
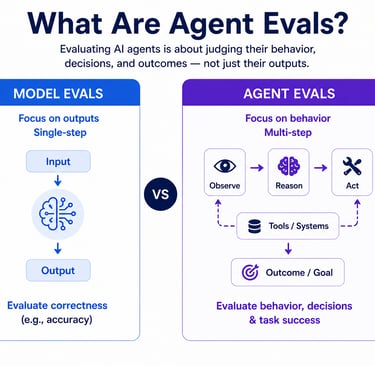
The Shift: From Outputs to Behaviours
To understand why Agent Evals matter, we need to understand what changed.
Traditional AI (Model-Centric)
Input → Output
Evaluate correctness (accuracy, precision, recall)
Static benchmarks
Agentic AI (Behavior-Centric)
Input → Reasoning → Actions → Outcomes
Multi-step workflows
Interaction with tools and systems
The shift is subtle but profound:
You are no longer evaluating answers—you are evaluating behavior over time.
This introduces complexity that traditional evaluation methods simply cannot handle.
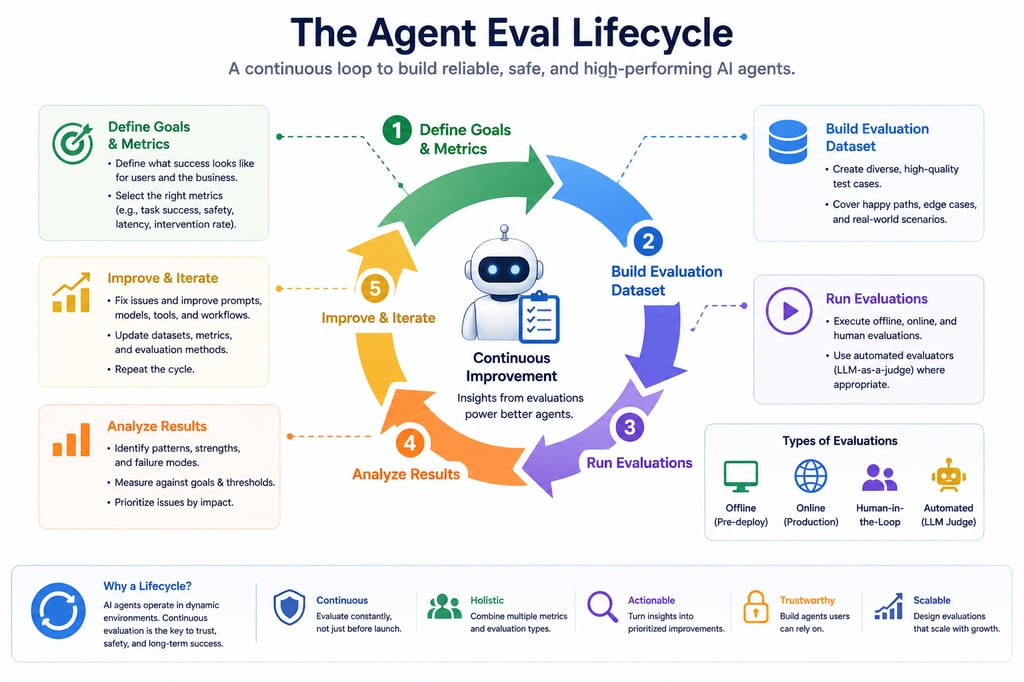
What Are Agent Evals?
Agent Evaluations are the processes, frameworks, and metrics used to assess how effectively an AI agent performs tasks, makes decisions, and operates across workflows.
They go beyond simple correctness and focus on:
Task completion
Decision-making quality
Safety and compliance
Consistency over time
User trust and experience
Instead of asking:
“Was the answer correct?”
We now ask:
“Did the agent achieve the intended outcome?”
“Did it follow the right steps?”
“Did it behave safely and responsibly?”
“Would a user trust it to do this again?”
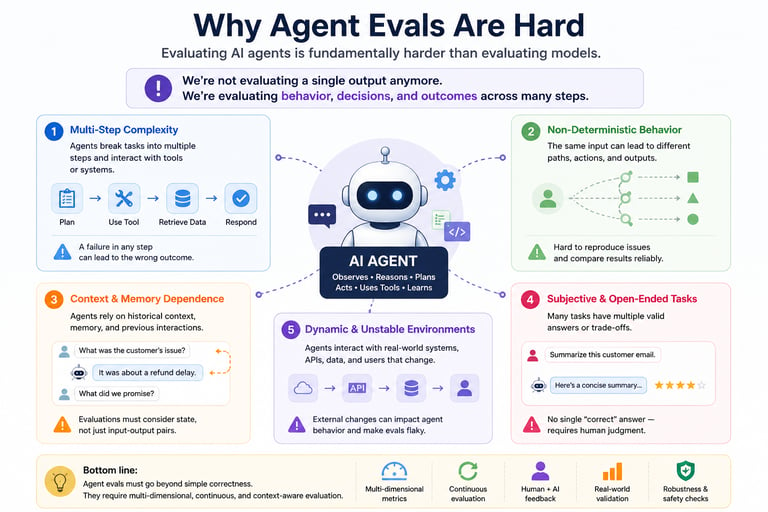
Why Agent Evals Are Fundamentally Hard
1. Multi-Step Workflows
AI agents rarely operate in a single step.
They:
Break down tasks
Call tools
Iterate decisions
Adjust based on feedback
A single failure in any step can cascade into a failed outcome.
This makes evaluation combinatorially complex.
2. Non-Deterministic Behavior
Unlike traditional systems, AI agents:
May produce different outputs for the same input
May take different paths to reach the same outcome
This makes reproducibility difficult.
You’re not testing one behavior—you’re testing a range of possible behaviors.
3. Context & Memory Dependence
Agents rely on:
Historical context
Session memory
External data sources
Evaluation must consider state, not just input/output.
A correct decision in isolation may be wrong in context.
4. Real-World Variability
Agents interact with:
APIs
Changing data
Human inputs
External systems
Static test cases are not enough.
You need dynamic, scenario-driven evaluation environments.
5. Subjective Quality
Many agent tasks involve:
Judgment
Prioritization
Trade-offs
There isn’t always a “right answer.”
This introduces the need for:
Human evaluation
Heuristic scoring
Context-aware metrics
Rethinking Metrics: What Should You Measure?
For Product Managers, this is the most critical shift.
Traditional AI metrics focus on:
Accuracy
Precision
Recall
But for agents, these are insufficient.
✔ Task Success Rate
Did the agent achieve the intended outcome?
This is your primary success metric.
✔ Decision Quality
Were the agent’s choices logical, relevant, and appropriate?
Not just what it did—but how it decided.
✔ Reliability / Consistency
Does the agent behave predictably across repeated runs?
Consistency builds trust.
✔ Safety & Constraint Adherence
Did the agent respect boundaries and avoid harmful actions?
This ties directly to AI safety and governance.
✔ Latency & Efficiency
How long did it take to complete the task?
How many steps were involved?
Efficiency impacts user experience and cost.
✔ Human Intervention Rate
How often did a human need to step in?
This is a powerful maturity metric:
High intervention → Low autonomy
Low intervention → Higher trust
✔ Recovery & Resilience
When the agent fails, can it recover?
This is often overlooked but critical in real-world systems.
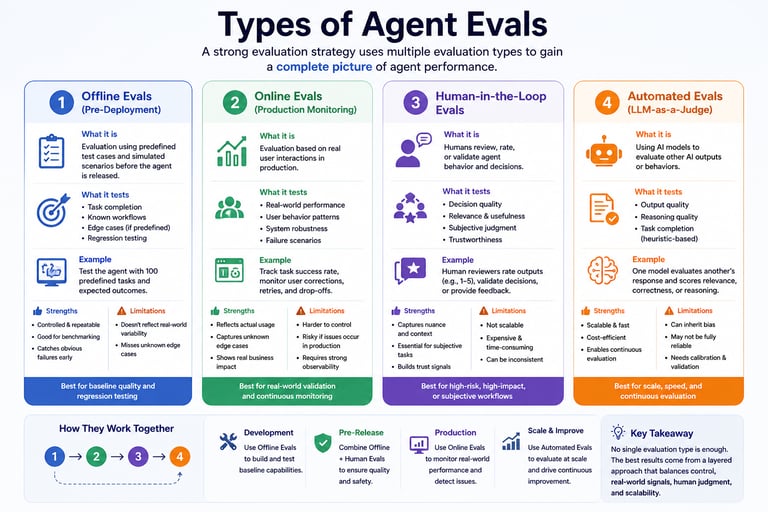
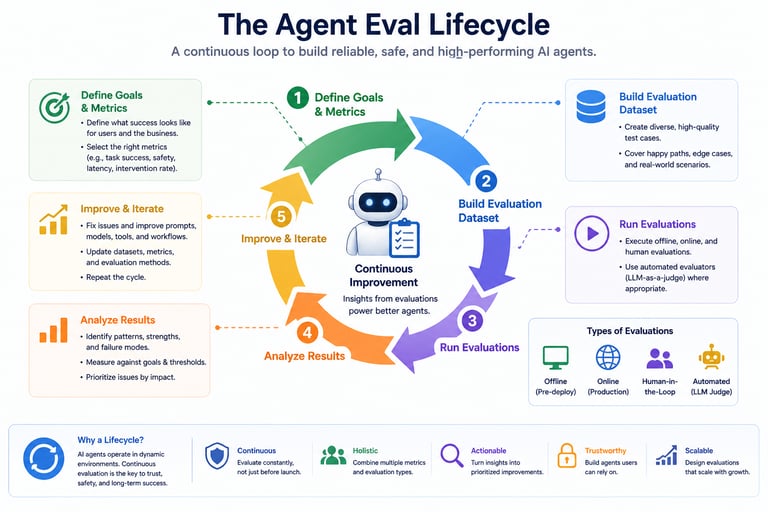
Types of Agent Evals
When building AI agents, a single evaluation method is not enough.
You need a combination of evaluation types to truly understand performance, reliability, and real-world behavior.
Here are the four core types of Agent Evals:
1. Offline Evals (Pre-Deployment)
Evaluation using predefined test cases and simulated scenarios, before the agent is released to users.
Controlled test scenarios
Simulated workflows
Benchmark datasets
👉 Useful for:
Early validation
Regression testing
1. Online Evals (Production)
Evaluation based on real user interactions in production.
Real user interactions
Live system monitoring
Continuous feedback loops
👉 Essential for:
Real-world validation
Detecting drift and failures
2. Human-in-the-Loop Evals
Humans review, rate, or validate agent behavior and decisions.
Experts review agent behavior
Rate decision quality
Provide feedback
👉 Critical for:
Subjective tasks
High-risk workflows
1. Automated Evals (LLM-as-a-Judge)
Using AI models to evaluate other AI outputs or behaviors.
AI systems evaluate other AI outputs
👉 Benefits:
Scalable
Fast
👉 Risks:
Bias
Overconfidence
👉 Requires calibration and oversight.
The real value comes from combining all four types:
The Product Manager’s Role in Agent Evals
Agent Evals are not just an engineering concern—they are a core product responsibility.
As a PM, you must:
1. Define “What Good Looks Like”
What does success mean for the user?
What outcomes matter most?
2. Align Metrics to User Value
Avoid over-indexing on technical metrics
Focus on business and user outcomes
3. Design for Measurability
Build systems that generate evaluation signals
Ensure observability from day one
4. Balance Automation vs Control
Decide when to allow autonomy
Define escalation and intervention points
5. Drive Continuous Improvement
Treat evaluation as an ongoing process
Feed insights back into product and model improvements
From Evaluation to Trust
There is a direct relationship:
Strong Evals → Reliable Behavior
Reliable Behavior → User Confidence
User Confidence → Adoption
Agent Evals are the foundation of Agent Trust
Without them:
You cannot validate performance
You cannot guarantee reliability
You cannot scale adoption
Final Thoughts
Agentic AI represents a new paradigm—not just in capability, but in responsibility.
The hardest problem is no longer building intelligence.
👉 It is ensuring that intelligence behaves reliably in the real world.
Agent Evals sit at the center of this challenge.
Because ultimately, success is not defined by:
What the AI can do
But by:
What the AI can do consistently, safely, and at scale